CS MSc Day May 31 Schedule!
2018-05-15
Seventeen MSc theses to be presented on May 31, 2018.
May 31 is the day for coordinated master thesis presentations in Computer Science at Lund University, Faculty of Engineering. Seventeen MSc theses will be presented.
N.B. For presentations taking place June 1 follow this link.
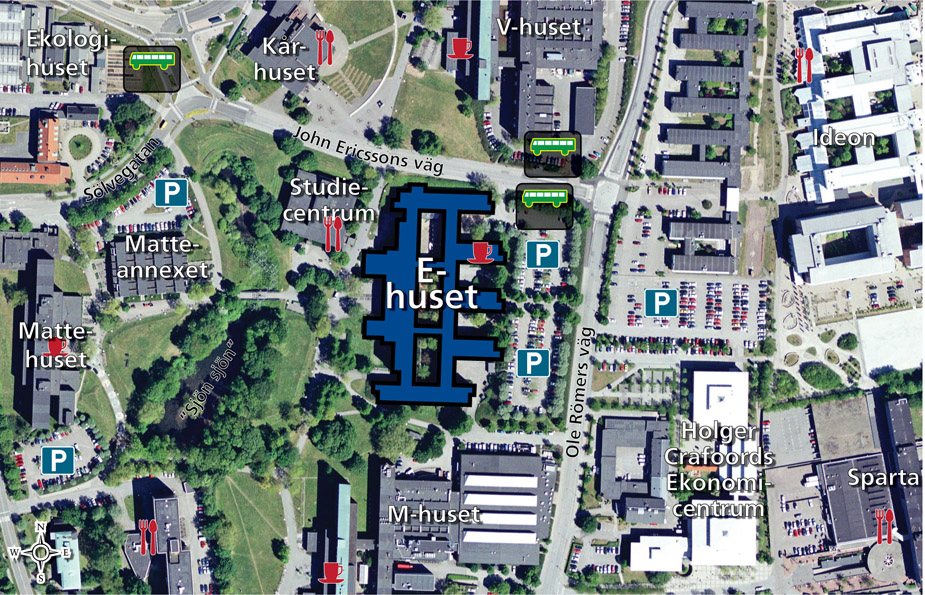
The presentations will take place in the E-house, rooms E:2116, E:2405 and E:4130. A preliminary schedule follows.
{kind=link}
Note to potential opponents: Register as opponent to the presentation of your choice by sending an email to the examiner for that presentation (firstname.lastname@cs.lth.se). Do not forget to specify the presentation you register for! Note that the number of opponents may be limited (often to two), so you might be forced to choose another presentation if you register too late. Registrations are individual, just as the oppositions are! More instructions are found on this page.
| E:2116 (Software) |
|---|
09:15
| PRESENTER | Måns Magnusson |
| TITLE | Orthagonal Range Searching and Graph Distances Parameterized by Treewidth |
| EXAMINER | Krzysztof Kuchcinski |
| SUPERVISOR | Thore Husfeldt (LTH) |
| ABSTRACT | In this master's thesis, we present an improved time complexity analysis of algorithms that calculate graph metrics; diameter, radius, eccentricities and Wiener index in weighted, undirected graphs. Our results show single-exponential dependence on the treewidth. These metrics can be calculated in polynomial-time using Dijkstra's algorithm, and in linear time for trees. For graphs with bounded treewidth, i.e., graphs with small cycles, the linear algorithm can be generalized by also finding points inside a d-dimensional box, so-called orthogonal range searching, which can be implemented using the data structure Range Trees. Part of the work has been submitted to a peer-reviewed, specialist conference, as a joint paper with Bringmann and Husfeldt. In this paper, attached as an appendix, we present new upper bounds by improving the analysis of Range Trees. This thesis provides more details to the background ideas and proofs covered in the paper, implementation, and empirical comparisons of running times. |
10:15
| PRESENTER | Rebecca Ritter |
| TITLE | Investigation of Applying DevOps Principles When Developing Device Software |
| EXAMINER | Ulf Asklund |
| SUPERVISORS | Martin Höst (LTH), Maria Hultzén (Axis Communications AB) |
| ABSTRACT | While the world has become more software driven, many organizations are disrupted as they need to deliver software faster while maintaining a high quality level. In such an environment, the concept of DevOps has risen in popularity. In this case study, software development processes were mapped from a DevOps perspective and a benchmarking study was conducted in order to learn from teams that have implemented monitoring processes within the case company. Based on these studies, a demonstrator that implements customer feedback data collection, visualization and analysis, was designed and evaluated. The results show that even though the industry leading case company has made an effort to transform its software development processes towards DevOps, there are still silos and hand-overs in place. The conclusion of the study claims that if the software development pipeline would get faster, monitoring data would be of larger interest which would lead to a more customer-driven software development. |
13:15
| PRESENTERS | Oscar Gunnesson, Daniel Jigin |
| TITLE | Using Existing Data to Answer Question Asked During Software Change |
| EXAMINER | Boris Magnusson |
| SUPERVISORS | Lars Bendix (LTH), Christian Pendleton (Praqma AB) |
| ABSTRACT | During software development, questions arise that can’t or are difficult to answer. Praqma AB has suggested that some of those questions can be answered by taking already existing data from software repositories and turn that into useful information. This thesis aims to identify those questions and explore how they can be answered using mining software repositories (MSR) and code analysis tools. We present 57 different questions, categorizing 15 as impact analysis and 6 as technical debt. The questions combined with theories are then turned into tool requirements. CodeScene, an MSR tool, is investigated to find support for the requirements and explored to find new features that could be turned into new requirements. Lastly, we present an implementation of a proof-of-concept tool which implements the requirements from this thesis. The studies showed that the tools could provide sufficient data to satisfy the requirements and present it in a suitable way. |
14:15
| PRESENTERS | Filip Stenström, Markus Olsson |
| TITLE | Improved precision and verification for test selection in Modelica |
| EXAMINER | Görel Hedin |
| SUPERVISORS | Niklas Fors (LTH), Jon Sten (Modelon AB) |
| ABSTRACT | Regression testing is a key concept to keep software in good shape, yet it can be a time consuming process. The testing time can be reduced by using a test selection technique which selects only the subset of tests that might have changed. We have defined and implemented a high precision regression test selection technique for the modeling language Modelica by using static dependency analysis. Our test selection technique provides better time savings compared to a previous technique. The time savings were computed for tests in certain Modelica libraries when one file or class was changed. We verified our dependency analysis by finding a subset of the actual dependencies and making certain they were in our analysis. The actual dependencies were found by mutating classes and seeing which test classes were affected. Furthermore, we evaluated our verification by analyzing the effectiveness of the different kind of mutations. |
| E:2405 Glasburen (Graphics) |
|---|
09:15 (No more places for opponents)
| PRESENTERS | Sebastian Hjelm, Mattias Gustafsson |
| TITLE | Vehicle Counting using Video Metadata |
| EXAMINER | Flavius Gruian |
| SUPERVISORS | Jörn Janneck (LTH), Yuan Song (Axis Communications AB) |
| ABSTRACT | The current field of object detection and image recognition is huge but not without complications. Processing large amounts of high resolution videos needs powerful hardware and also risks breaching the privacy of those who are recorded. In times of increasing demand for decentralized solutions and stricter privacy protection regulations being put in place a new approach is needed. We present an alternative to traditional object detection in video where we analyze changes to its metadata over time rather than the content of the video frames. This approach has several benefits over traditional object detection: it is incredibly fast, lightweight and protects the privacy of its subjects. We have trained and evaluated several neural network models tasked with detecting and counting vehicles in various scenes and have achieved accuracies above 95%. Finally, we take the first steps toward a decentralized solution running entirely on embedded devices. |
10:15
| PRESENTER | Einar Nordengren |
| TITLE | Procedurell generering av spelinnehåll |
| EXAMINER | Jörn Janneck |
| SUPERVISORS | Michael Doggett (LTH), Torbjörn Söderman (King Mobile AB) |
| ABSTRACT | Over the years, game development has grown into a large business. Due to the ever-increasing demand for new content, there is much time, money, and effort that can be saved using automatic generation. In this project, we have developed a procedural content generation tool to automatically define spawn points in a wave-based shooter game. Our intention was to create missions that follow the designers desired difficulty and intensity levels, and that can mimic human behavior. We evaluated the project through a survey, letting several people play and rate the wave difficulty, intensity, and author. The results showed that it was possible to generate waves that somewhat followed the direction of the difficulty and intensity levels, however impossible to mimic human behaviour. We arrived at the conclusion that this was due to the nature of the problem: assuming what controls the difficulty and intensity measures is easier than predicting human design. |
13:15 (No more places for opponents)
| PRESENTER | Christian Oliveros |
| TITLE | Improved Sampling for Temporal Anti-Aliasing |
| EXAMINER | Flavius Gruian |
| SUPERVISOR | Michael Doggett (LTH) |
| ABSTRACT | Anti-aliasing is a key component of modern 3D computer-generated imagery. For Real-Time image generation in applications such as games, it is important to increase the sampling rate per pixel to improve overall image quality. But increasing sampling can be expensive, especially for current Deferred Rendering architectures. An innovative solution to this issue is the Temporal Anti-Aliasing (TAA) technique which combines samples from previous frames with the current frame samples to effectively increase the sampling rate. In this thesis, we will explore methods to improve the quality of TAA by using edge detection, of both color and depth, and triangle indexing to ensure only samples belonging to the current frame pixels are blending together. Our objective is to reduce ghosting and other TAA artifacts created with current implementations. Quality improvement will be evaluated by comparing TAA generated images to ground truth images generated by using much higher sample counts that would not be practical in real-time. The improved TAA was tested using MSE, PSNR, and SSIM against the original implementation and other current Anti-Aliasing techniques. The results obtained showed that the improvements applied to TAA satisfied the expectations, surpassing in quality the other techniques. On average, the PSNR values were around 39 and SSIM values above 0.99. |
14:15
| PRESENTERS | Daniel Cheveyo, Arvid Carlman |
| TITLE | Automated classification of graphical artefacts in 3D graphics verification |
| EXAMINER | Michael Doggett |
| SUPERVISORS | Flavius Gruian (LTH), Rasmus Persson (ARM) |
| ABSTRACT | System testing is performed when developing 3D graphics hardware and drivers. A crucial aspect when performing system testing is comparing a given output image of a specific scene to its corresponding reference image. There are many methods of quantifying the difference between two images, most of which only produce a scalar value as a measurement. To save time in the development process by not manually classifying the graphical artefacts in these images, an automated classification tool was produced, which is described in this paper. Given a relatively small set of data, a certain number of classes were determined based on the similarities of the artefacts. When tested on the available data the classification had a success rate of 73 %. |
15:15
| PRESENTER | Jakob Folkesson |
| TITLE | Monoscopic rendering at a distance in consumer head-mounted displays |
| EXAMINER | Michael Doggett |
| SUPERVISOR | Tomas Akenine-Möller (LTH) |
| ABSTRACT | Since Oculus released their head mounted device OculusRift more and more companies have been developing similar products - the advantage of which is that they provide viritual reality through stereoscopic 3D technology. Although these head mounted devices give the user immersion that is hard to match, it comes with the drawback of requiring twice the amount of rendering (once per eye). This work proposes an alternative way of rendering to a stereoscopic screen by rendering in stereo only up to a certain distance and then switching to monoscopic rendering after what we have called the stitch distance. This could potentially reduce rendering cost by allowing objects further away than the stitch distance to be rendered only once. We performed a user study measuring the ability to detect artifacts dependent on the stitch distance however no such link was discovered. |
| E:4130 LUCAS (A.I.) |
|---|
09:15
| PRESENTER | Axel Nyström |
| TITLE | Investigating the effect of adding weather to a random forest classifier that predicts the hospitalization of patients with end-stage renal disease |
| EXAMINER | Elin Anna Topp |
| SUPERVISORS | Jacek Malec (LTH), Mattias Sellin (Lytics Health AB) |
| ABSTRACT | Patients with end-stage renal disease (ESRD) frequently suffer complications that lead to hospitalization, and predicting such hospitalizations ahead of time is potentially of great benefit. Lytics Health AB has developed an AI system that uses physiological measurements from the patients to train a Random Forest classifier that attempts to make such predictions. But physiological measurements alone does not paint a complete picture of the patient risk profile. It is believed that weather might contain one of the missing pieces, since research has shown it to correlate with various diseases that are common comorbidities for patients with ESRD. In this thesis the effect of adding weather measurements to an already developed AI system was investigated. A test environment was created where different combinations of measurements like wind, precipitation, temperature, atmospheric pressure and humidity could be evaluated on different patient groups. In the end, no significant improvement due to weather was observed. |
10:15 (No more places for opponents)
| PRESENTERS | Andy Truong, Daniel Hellström |
| TITLE | Clustering and Classification of Test Failures Using Machine Learning |
| EXAMINER | Flavius Gruian |
| SUPERVISORS | Erik Larsson (LTH), Lars Viklund (Axis Communications AB) |
| ABSTRACT | Verification is an important part of the hardware design process. Thorough verification requires a large number of test cases. To facilitate debugging in verification, test failures are clustered and classified according to their root causes. Currently, this is performed by manually examining log files. This thesis investigated how machine learning can be applied to automate this process. We used Python and Scikit-learn to evaluate and compare machine learning algorithms for clustering and classification of test failures. Our dataset consisted of 12500 log files generated by equally many test cases. We compared 9 classification algorithms and 3 clustering algorithms. We also investigated the impact of dimensionality reduction on both computation time and performance. The most suitable clustering algorithm was DBSCAN with AMI and ARI scores of 0.593 and 0.545 respectively. The most suitable classification algorithm was random forest with an accuracy of 0.907 and an F1-score of 0..913. |
11:15 (No more places for opponents)
| PRESENTERS | Anders Buhl, Hugo Hjertén |
| TITLE | Evaluation of Artificial Neural Networks for Predictive Maintenance |
| EXAMINER | Flavius Gruian |
| SUPERVISORS | Patrik Persson (LTH), Johan Lindén (Jayway), Andreas Kristiansson (Jayway) |
| ABSTRACT | This thesis explores Artificial Neural Networks (ANNs) for predictive time series classification for Predictive Maintenance (PdM). Time slicing and time shifting are methods used, to enable the models to find features over time, and to predict into the future, respectively. Architectures of increasing complex- ity are explored for Feed Forward Neural Networks (FFNNs), Convolutional Neural Networks (CNNs) & Long Short-Term Memory (LSTM) networks, of which the best performing are compared. CNNs & LSTM are found to per- form better than FFNNs since they are designed to handle sequences of data. The research shows that a model with high accuracy might in fact be a bad model for PdM. Additional metrics such as Confusion Matrices and Receiver Operating Characteristic (ROC)-curves are needed to evaluate models. This thesis shows that consistent, representative and a lot of data of good quality is needed for a well performing ANN. ANNs for PdM reduces the required do- main knowledge, and perform well for frequent samples, i.e. normal classes, but less so for unusual classes. |
13:15 (no more place for opponents)
| PRESENTERS | Otto Nordander, Daniel Pettersson |
| TITLE | Classifying energy levels in modern music using machine learning techniques |
| EXAMINER | Jacek Malec |
| SUPERVISOR | Pierre Nugues (LTH), Johan Brodin (Soundtrack Your Brand AB) |
| ABSTRACT | Music is a big part of many people's lives, certain characteristics of music may be more appropriate in certain situations, depending on mood, setting, or time of day. One interesting characteristic is energy level, by categorizing music into different energy levels a user is given the means to finding more fitting music.\ We present a solution based on artificial neural networks and transfer learning that is able to classify 10 different energy levels on a linear scale from 1 to 10 independent of genre. The proposed solution reaches a mean distance of less than 1 from the annotated class on a broad range of music genres. We believe this is within expectation given that the problem is difficult even for a human. |
14:15 (No more places for opponents)
| PRESENTER | Viktor Stagge |
| TITLE | Categorizing Software Defects using Machine Learning |
| EXAMINER | Jacek Malec |
| SUPERVISORS | Kenneth Ulrich (Sony Mobile Communications AB), Markus Borg (LTH) |
| ABSTRACT | We analyze how automatically generated crash reports can be used to aid in the process of software defect categorization. The crash reports are automatically generated logs, which vary widely in both format and in information content. Each crash report used is linked to its corresponding, human-written bug report. The problem is handled as a long text-based classification problem. Several different machine learning techniques are compared. Amongst these is our own Keras-based implementation of a Hierarchical Attention Network, with which we achieved an accuracy of 72.5% on Severity prediction, and an accuracy of 51.4% on Responsible Group prediction. |
15:15 (no more place for opponents)
| PRESENTERS | Hampus Londögård, Hannah Lindblad |
| TITLE | Improving Open Street Map Way Components with Neural Networks |
| EXAMINER | Jacek Malec |
| SUPERVISORS | Pierre Nugues (LTH), Thomas Hermansson (Åf) |
| ABSTRACT | OpenStreetMap is an open source of geographical data where contributors can change, add or remove data. Since anyone can become a contributor, the data set is prone to contain data of varying quality. In this work, we focus on smoothing name tags for Way components by finding missing names, correcting misspellings and flagging anomalies. The spell corrector is the most in-depth system in this report where the aim is to achieve spell correction in a new way. Spell correctors in related works have a context of sentences and a labeled corpus for reference. In addition, spell correctors often struggle with new words. We however show that a spell corrector built as a neural network, without the use of context and labeled corpus, is possible. We also work with edge cases since Danish way names are compounds of words. For evaluation we used a manually created data set of Way names. |
16:15 (no more place for opponents)
| PRESENTERS | Hanna Andréason, Christopher Nilsson |
| TITLE | Improving efficiency of customer support through machine learning -- An applied approach |
| EXAMINER | Jacek Malec |
| SUPERVISOR | Pierre Nugues (LTH) |
| ABSTRACT | Customer Support is an expensive service and not easily scalable department. Support Tickets from customers could reveal valuable information and insights can be given by labeling the tickets. Today the labels are set manually for each ticket by the employees at the Customer Support department at Telavox. In this thesis, we explore if we can multinomially classify the support tickets from a predetermined set of tags, based on their textual representation. By doing this the efficiency of labeling support tickets could be increased. We explore different classification algorithms, clustering algorithms and neural nets to find the best solution and we explore different data representations. We found that a Ridge Regression Classifier gave the best result and that it is not always easy to classify some tickets by looking only at the text. Finally, we develop an application that could be used to receive the probability of which label that is best suited for the ticket. Our final model suggest the correct label in the top three suggestions 88,3% of the times. |
17:15
| PRESENTER | Anders Schill |
| TITLE | Customer Churn Prediction in an Online Streaming Service |
| EXAMINER | Jacek Malec |
| SUPERVISOR | Pierre Nugues (LTH) |
| ABSTRACT | This thesis analyzes the application of different classification models to the churn prediction problem and different techniques for handling common hurdles in this domain such as imbalanced datasets. More specifically, the study was conducted in collaboration with Spotify and the end goal was to produce a model for identification of users that are likely to cancel their subscription to the paid premium service within the next 30 days, using recent historical data. Logistic regression, gradient boosted trees and feed-forward neural networks were paired with different types of preprocessing and feature selection methods which resulted in a model that could potentially help boost profitability in targeted marketing campaigns. |