CS MSc Day August 25 Schedule!
2017-08-10
Ten MSc theses to be presented on August 25, 2017.
August 25 is the day for coordinated master thesis presentations in Computer Science at Lund University, Faculty of Engineering. Ten MSc theses will be presented.
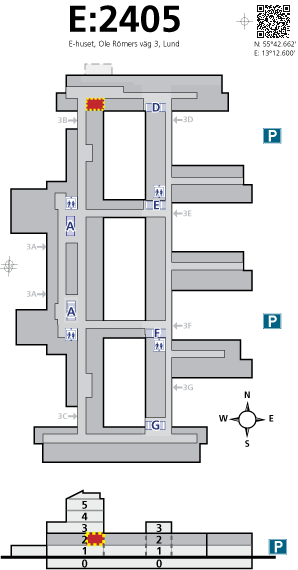
The presentations will take place in the E-house, the Software Development track in room E:2405 (Glasburen) and the A.I. track in room E:4130 (LUCAS). A preliminary schedule follows.
{kind=link}
{kind=link}
Note to potential opponents: Register as opponent to the presentation of your choice by sending an email to the examiner for that presentation (firstname.lastname@cs.lth.se). Do not forget to specify the presentation you register for! Note that the number of opponents may be limited (often to two), so you might be forced to choose another presentation if you register too late. Registrations are individual, just as the oppositions are! More instructions are found on this page.
| E:2405 (Glasburen) Software Development |
|---|
09:15
| PRESENTERS | Johan Nilsson, Philip Pedersen |
| TITLE | Web-based Requirements Engineering & further development of reqT |
| EXAMINER | Björn Regnell |
| SUPERVISOR | Johan Linåker (LTH) |
| ABSTRACT | reqT is an open-source Requirements Engineering language, which is used in the laboratory sessions and project of the course ETS170 - Requirements Engineering. It has been noted that the language in its current form can be difficult to use for non-programmers, and as such, the aim of this thesis has been to solve this issue by developing a web-based application of reqT where the user can build their requirements model using a hierarchical tree structure. In conjunction with the development of the system, a large focus has been placed on observing what usability aspects need special consideration when developing a user interface for requirements modelling. The application was primarily built using Scala.js and React. |
10:15
| PRESENTERS | Kasper Rundquist, Erik Hedblom |
| TITLE | Safe test selection for Modelica using static analysis |
| EXAMINER | Görel Hedin |
| SUPERVISORS | Niklas Fors (LTH), Johan Ylikiiskilä (Modelon AB), Jonatan Kämpe (Modelon AB) |
| ABSTRACT | During software development, testing of software can be very time consuming. We have developed a safe regression test selection technique using static analysis, for the modeling language Modelica. When a user changes a Modelica model, our technique will exclude tests that are guaranteed not to be affected by the change. Since Modelica tests usually has relatively long running times there is much time to save. As far as we know test selection has previously not been attempted for Modelica. To perform the test selection we have implemented a dependency analysis in an existing Modelica compiler. We have evaluated our technique and tried to assess how much time that can be saved. When we look at the commit history of the Modelica Standard Library and compare running all tests with only running the tests selected by our test selection, the time saved for running the selected tests is 56% of the time it takes to run all tests. |
11:15
| PRESENTER | Gustav Hochbergs |
| TITLE | Reactive programming and its effect on performance and the development process |
| EXAMINER | Jörn Janneck |
| SUPERVISORS | Patrik Persson (LTH), Johan Frick (Playtech One Sports) |
| ABSTRACT | The focus of this master's thesis is to evaluate the effect of reactive programming on Playtech One Sports content server. The effect is evaluated from a performance aspect and from a development process aspect. The content server is working in real-time and is required to have low latency and high throughput of processing of data. Three types of reactive prototypes of the content server were implemented with different execution contexts. The results showed that reactive programming can increase the performance during high loads. The solutions performed similarly during low load. During high load one prototype stood out with 100% of throughput and low latency. This prototype had an execution context in the thread which subscribed to the result from the executed callback methods. The development process did not change significantly, but reactive programming added complexity to the code and the need for a developer with extensive knowledge in reactive programming. |
13:15
| PRESENTERS | Tobias Landelius, Viktor Attoff |
| TITLE | Managing and utilizing dependencies between components in component-based systems |
| EXAMINER | Ulf Asklund |
| SUPERVISORS | Lars Bendix (LTH), Fredrik Stål (Softhouse Consulting Öresund AB) |
| ABSTRACT | When developing software systems the advantages in using a modular architecture are many, e.g. scale-ability, reusability and the ease of making changes. However, this type of architecture creates problems regarding how modules depend on each other. Today many kinds of dependencies are not documented and left out of the development process. With no generalized structure or definition of dependencies, developers might overlook problems that could be found proactively. By literature research and qualitative interviews of industry people in various roles, this thesis elicits the core problems around dependencies. Managing dependencies is seen as complex and dependency related problems can have a severe impact on development if caught late. The thesis presents that overview-oriented dependency management can benefit software development in terms of estimating change-impacts and cost-of-change, aiding communication during development and optimizing the amounts of tests that have to be run after a change. |
14:15
| PRESENTERS | Fredrik Karåker Sundström, Johan Bäckström |
| TITLE | Implementing and Evaluating the Use of Automatic Tests for Architectural Rules |
| EXAMINER | Martin Höst |
| SUPERVISORS | Elizabeth Bjarnason (LTH), Robert Lagerstedt (Robert Bosch AB) |
| ABSTRACT | The development of high quality software often demands good software architecture. The architecture is often partly defined by guidelines that needs to be communicated and enforced in the project. We have investigated how this can be achieved by implementing automatic checking of the architectural guidelines in the tool-chain of a software project. We concluded that it is an efficient way of both communicating the guidelines to the developers and ensuring that they are followed. It was shown that this worked well as a compliment to the manual code reviews that was previously used in the project for ensuring that the architectural guidelines were followed. Only a third of the breaches found by the automatic checkers were found by the manual reviews which shows the potential and need for automation. The checkers can also save time and effort for the project members since a lot of manual work can be avoided. |
| E:4130 (LUCAS) A.I. |
|---|
09:15 (N.B. Changed time)
| PRESENTER | Anton Lundborg |
| TITLE | Text classification of short messages (Detecting inappropriate comments in online user debates) |
| EXAMINER | Jacek Malec |
| SUPERVISORS | Pierre Nugues, (LTH), Gustav Hjärn (Ifrågasätt Media AB) |
| ABSTRACT | Almost every large Swedish online newspaper has disabled comments under their articles due to problems with hateful and offensive comments. In this Master’s thesis, we explore different ways to detect toxic comments using machine learning. We carried out a comparison of classification algorithms and evaluated a number of different feature sets with the goal of optimizing accuracy for the classification of comments. We carried out the experiment with a manually labeled data set. The best classifier was logistic regression with a F-Score of 0.47 and recall of 0.50. We incorporated the classifier into a moderation tool for comments to help streamline the moderation process. |
13:15
| PRESENTERS | Filip Månsson, Fredrik Månsson |
| TITLE | News text generation with adversarial deep learning |
| EXAMINER | Jacek Malec |
| SUPERVISORS | Håkan Jonsson (Sony Mobile Communications AB), Pierre Nugues (LTH) |
| ABSTRACT | Machines have previously been used to generate natural language (or text).We apply a rather new technique within the machine learning subject called Generative Adversarial Networks to the art of natural language generation;more specifically we try to generate news text articles in an automated fashion. To do this we try a few different architectures and representation of text,evaluate the results and use the information retrieved from the results to create a model that should give the best result. For evaluation we use perplexity and human evaluation. We also look at the token distribution to see which model captures the texts most successfully.We show that it is possible to use Generative Adversarial Networks to generate sequences of tokens that resembles natural language but there is more to be asked. Further hyper parameter tuning and using a narrower subjected corpus could improve the output. |
14:15
| PRESENTERS | Erik Gärtner, Axel Larsson |
| TITLE | Constructing a multilingual relation extraction system using natural language processing and neural networks |
| EXAMINER | Jacek Malec |
| SUPERVISORS | Pierre Nugues (LTH), Håkan Jonsson (Sony Mobile Communications AB) |
| ABSTRACT | A large amount of information is available on the internet in the form of natural language in written form. In order to make the information useful for computer systems, such as knowledge graphs and question-answering systems, the information must first be structured. In this thesis we construct a multilingual system that in a semi-unsupervised manner can learn to extract certain type of stated facts. To achieve this the system uses natural language processing techniques with neural networks and word embeddings. Our evaluation shows promising results; it achieves good precision on select relations and further improvements are most likely possible in the future. |
15:15
| PRESENTERS | Alexander Ekdahl, Joacim Åström |
| TITLE | Subjective matching of products using Machine Learning |
| EXAMINER | Jacek Malec |
| SUPERVISORS | Elin Anna Topp (LTH), Hans Peter Hagblom (Jayway AB) |
| ABSTRACT | When insurance companies calculate compensation for products no longer on the market, they need to identify an equal product for valuation. Subjectively matching products poses a unique challenge with many-to-many pairing, which is currently handled by an algorithm that requires day-to-day maintenence. This thesis investigates current methodologies and tools and presents unique machine learning methods in an attempt to improve results and eliminate manual labour. By combining a multilayered neural network with cosine proximity comparison, this thesis shows promising results in that a fully automated machine learning model can be implemented and facilitate the systems currently in use. |
16:15
| PRESENTERS | Hannes Sandberg, Michal Stypa |
| TITLE | Improving the semantic accuracy and consistency of OpenStreetMap using modern machine learning techniques |
| EXAMINER | Elin Anna Topp |
| SUPERVISORS | Pierre Nugues (LTH), Stefan Christiansen (ÅF) |
| ABSTRACT | OpenStreetMap (OSM) is a collaborative project with the aim of creating a free editable map of the world. It is considered one of the most prominent examples of Volunteered Geographic Information with the majority of data generated and edited by user contributors. The OSM dataset describes real-world phenomena by associating a set of attributes to geographic primitives. The semantic meaning of each entity is described using a structured key/value pair called tags. Due to their simple and open semantic structure, the approach often results in noisy, inconsistent and ambiguous data. In this thesis, we explore possible methods of improving the quality of OpenStreetMap data in terms of attribute accuracy and consistency using modern machine learning techniques. During the process, we identify major challenges together with viable solutions in an end-to-end application. The resulting system is capable of highlighting aberrations and predicting true values for every attribute with at least 80% accuracy depending on the attribute. |