A Web Crawler
Objectives
In this assignment, you will program a Web crawler. A Web crawler is a program that reads web pages and that indexes the words they contain. The crawler starts from a single page or a set of pages and follows the links it finds in them. In your program, we will set aside the indexing part and focus on the crawler. The objectives are to:
- Create a crawler
- Collect page addresses
- Collect e-mail addresses
- Review the URL class
- Understand the URLConnection class
- Understand a Java HTML parser
Summary of the Work
Each group will have to:
- Write a monothreaded crawler.
- Use a HTML parser to parse the pages. This feature is compulsory. You must not use regular expressions to extract the links. You have to extract them with a parser and you should use jsoup.
- Extend the crawler to a multithreaded program.
Reading Assignments
- Read Chapters 5 and 7 on URL and URLConnection in the book Java Network Programming by Elliotte Rusty Harold as well as the course slides on HTML and XML;
- Read the description of the Become system here and test it here
Programming
Below are the main parts you will implement. Start with the monothreaded search and then extend it to a multithreaded program. Each part lists unsorted points that your program must fulfill.
Search
- Your program will start from a single URL address, for example:
http://cs.lth.se/eda095/ or http://cs.lth.se/pierre_nugues/. - Your crawler will analyze the current Web page beginning with the start address, collect all the valid URL addresses, and continue with the addresses the page is pointing to. The program will run until it has no more address to collect or it has reached a limit, say 1000 links.
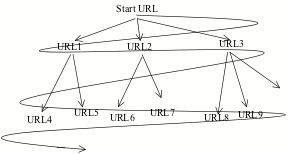
- A breadth-first search is a possible strategy to explore a graph like the Web, see the figure below:
- The crawler reads the start page and finds three addresses, URL1, URL2, and URL3, in it, that it appends to the end of a queue.
- The crawler uses the address that is the first of the queue (URL1), reads this page, and finds two addresses that it appends to the end of the queue.
- The crawler uses the next address in the queue (URL2), reads it, and so on.
Parsing the pages
- The crawler only needs to read pages containing text. You will select these pages using their the MIME type and the getContentType() method from URLConnection. In addition, you can also use the URL suffix.
- The crawler should not visit twice a same Web page.
- The crawler will extract URL addresses from the HTML web pages using the jsoup parser. You can reuse and modify the program seen in the lecture (go to the slide: Extracting links with jsoup). You will consider at least these three types of links:
- <a href="http://cs.lth.se/pierre_nugues/"></a>
i.e. the href attribute that is in the a element (both relative and absolute addresses). - <a href="mailto:Pierre.Nugues@cs.lth.se">
i.e. see above but you must have a specific processing for the mailto tag (see below). - <frame src="myframe.html">
i.e. the src attribute that is in the frame element (This corresponds to pages that use frames).
- <a href="http://cs.lth.se/pierre_nugues/"></a>
- To build a URL from a string, you can use the constructor: URL(String)
To build a URL from a base URL and a string relative to it, you can use the constructor: URL(URL, String)
Consider the address http://cs.lth.se/pierre_nugues/ and the relative address undervisning.html. You can build the absolute URL corresponding to the second address http://cs.lth.se/pierre_nugues/undervisning.html using:
URL(new URL("http://cs.lth.se/pierre_nugues/"), "undervisning.html") - The crawler must store all the URLs from HTML web pages and all mailto addresses in two separate lists.
When the crawler has finished to collect them, it will print them out or save them in a file:
- List
of URLs:
http://cs.lth.se/pierre_nugues/
http://cs.lth.se/pierre_nugues/undervisning.html
http://cs.lth.se/pierre_nugues/research.html
http://cs.lth.se/pierre_nugues/publi.html
http://cs.lth.se/pierre_nugues/index_a.html
http://cs.lth.se/pierre_nugues/index_f.html
... - List of addresses:
mailto:Pierre.Nugues@cs.lth.se
mailto:Peter.Moller@cs.lth.se
- List
of URLs:
Multithreading the crawler
Instead of using one single thread, you will extend your program to run simultaneous crawlers in the program. On his machine, Pierre Nugues could collect 2000 URLs in 11:30 minutes with a one-thread program and in 3:30 minutes with 10 threads. Can you explain why?
Here are some unsorted points you can consider to make your crawler multithreaded. They just form a suggestion. You can use the Executors class instead of Thread.
- The program can consist of three classes: Main that initializes the data and creates the objects, Processor that extends the Thread class and Spider that process the data.
- Main creates and starts 10 Processor threads.
- Spider uses two lists: traversedURLs and remainingURLs.
- Main initializes the remainingURLs list with one element (the start address).
- Each thread is a loop that takes the first unprocessed URL from remainingURLs and analyzes it.
- You must write methods so that the thread can access the lists and append the results to the end of the traversedURLs list.
- Access to the lists and processing of data must be thread safe.